


Nargiz Askarbekkyzy is an AI researcher at Sentience who graduated from KAIST with a major in computer science. She has previously worked in the KAIST lab where she designed and developed retargeting/redirection technology for VR apps. Currently, she is researching and developing deep reinforcement learning models to enhance gaming experiences at Sentience.
Intro
In 2016, Google DeepMind presented a computer program AlphaGo [1], which crashed the world champion in the notoriously challenging game - Go. Just three years later, OpenAI’s team consisting of artificial intelligence (AI) players in Dota 2, called OpenAI Five, beat The International 2018 (Dota 2 world tournament) champions [2]. These victories did not stem from a stroke of pure luck. They resulted from a sophisticated approach rooted in the principles of reinforcement learning. This is the first post in our blog series dedicated to reinforcement learnings, and today, we will delve into reinforcement learning realm, explaining its core principles and intricacies.
Reinforcement learning is a paradigm within the broader scope of machine learning. It is a task where an agent learns a behavior by interacting with a dynamic environment through a series of trials and errors [3]. Unlike its counterparts, supervised and unsupervised learning that rely on a static dataset, reinforcement learning has an interactive element focusing on decision-making (Figure 1).
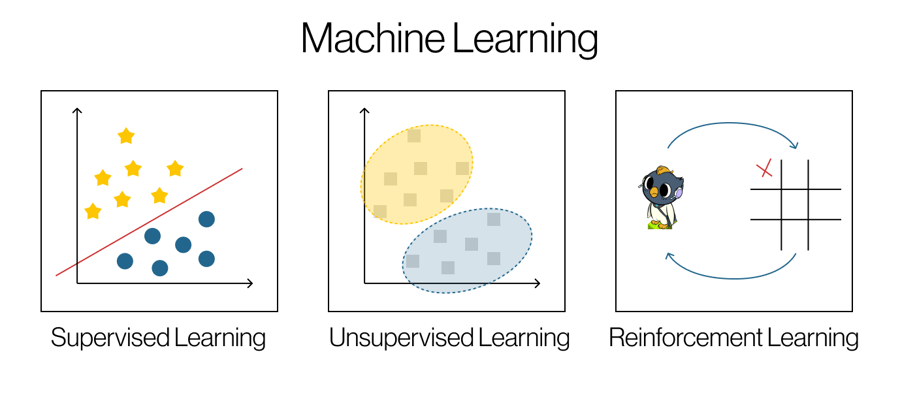
Components and Terms of Reinforcement Learning
What is an agent? What is an environment? Before we explain how the computer program can learn, let us introduce several components and terms central to further understanding:
- Agent is a sort of bot that chooses and takes action.
- Environment is the world in which the agent operates. For example, in chess, the chess board and pieces are the environment, and a player-bot is an agent.
- Action is any possible interactions that the agent can choose to carry out.
- State is information about the current condition of the environment.
- Reward is a point given to the agent as an outcome based on its action.
- Policy is a strategy, guiding the agent's actions in response to the environmental state.
- Episode is a sequence of interactions from the initial state to a terminal state (e.g., one chess game).
Cyclic Process of Reinforcement Learning
Whoo! Now, we should be ready!
At its core, reinforcement learning is a cyclic process. The agent observes the state of the environment. It has a set of available actions. It chooses one from the set. The action earns an agent rewards, which can be positive, negative, or zero. It updates its policy based on the reward. The action changes the environment, creating a new state, and the cycle repeats (Figure 2) [4].
.png)
The primary goal for the agent is to maximize cumulative rewards over time. The agent is not told which action to take but only the impact of the action in the form of rewards. Therefore, with each iteration, the agent revisits its decision-making process or policy, learning to prioritize actions that lead to favorable outcomes. As it earns more experience, the agent gradually is better at the task.
Algorithms in Reinforcement Learning
There are various algorithms and methodologies employed in reinforcement learning. They could generally be divided into two groups:
- Value-Based Methods. These methods estimate a value function. It is a function that returns how good or beneficial it is for an agent to be in a given state [4].
- One of the value functions is Q-function. It estimates the expected cumulative reward for a given action a in a specific state s [4].
- Policy-Based Methods. These methods optimize and learn the policy directly. They do not rely on a value function. While policy is a strategy, it is represented by a mapping from the state to the probability distribution over all actions [4].
In more complex settings, where the action space is large or the environment is sophisticated, using these methods gets complicated. It gets difficult to remember the relationships between all possible states and all possible actions. To solve this problem, we can utilize deep neural networks (NN), making it deep reinforcement learning (DRL).
For example,
- As a value-based method, Deep Q-Network (DQN) applies deep neural network to approximate the Q-function [5].
- As a policy-based method, Proximal Policy Optimization (PPO) uses deep neural networks to update the policy [6].
Here, at Sentience, we have explored both DQN and PPO to develop smart bots for our game, South Pole Bebop.
Conclusion
Reinforcement learning is a powerful tool that can produce great results once harnessed. In the next blog, we will take a practical approach. We will share our experience working on a deep reinforcement learning model for our game, South Pole Bebop. We will also include the resources, libraries, and tools the readers can use to apply reinforcement learning in their use case. So stay tuned for upcoming posts, where we will unravel AI together!
Read our next post: Deep Reinforcement Learning: A Practical Guide for Game Devs
References:
[1] “AlphaGo,” Google DeepMind. https://deepmind.google/technologies/alphago/
[2] “OpenAI Five defeats Dota 2 world champions,” openai.com. https://openai.com/research/openai-five-defeats-dota-2-world-champions
[3] L. P. Kaelbling, M. L. Littman, and A. W. Moore, “Reinforcement Learning: A Survey,” Journal of Artificial Intelligence Research, 1996, doi: https://doi.org/10.48550/arXiv.cs/9605103.
[4] R. Sutton and A. Barto, “Reinforcement Learning An Introduction second edition.” Available: https://www.andrew.cmu.edu/course/10-703/textbook/BartoSutton.pdf
[5] V. Mnih et al., “Playing Atari with Deep Reinforcement Learning,” arXiv.org, 2013. https://arxiv.org/abs/1312.5602
[6] J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal Policy Optimization Algorithms,” arXiv.org, 2017. https://arxiv.org/abs/1707.06347




