


Intro
Welcome to Part Two of our blog series about Deep Reinforcement Learning! In our previous post, we introduced the fundamentals of Reinforcement Learning (RL). We discussed how agents learn to perform the given tasks through trials and errors, earning rewards for good decisions and facing penalties for bad ones. We also touched on how Deep Learning empowers RL, making it Deep RL. If you missed the introductory post, you can catch up here.
Today, let's take a practical approach and explore how you can apply Deep RL to train an agent that excels in your custom game!
Let’s dive in!
1. Choose your target Game
First and foremost, you need to prepare the game itself – the playground where your agent will build and sharpen its skills. Verify the correctness of your game mechanics and ensure that you can interact with it programmatically. Usually, the reinforcement learning frameworks leverage Python programming language. Therefore, for simple games, you should consider exploring open-source frameworks like Pygame. However, if your game is developed in Unity, you can use Unity’s ML agents as an RL framework.
If you intend to build a game specifically for reinforcement learning experiments, the Gymnasium library, which we will discuss in the next step, is a suitable option. Nonetheless of the game, it is crucial to easily trace the information about the game. We need to capture how different decisions affect the game state.
In Sentience, we are working with our very own South Pole Bebop.

2. Define an Environment
If you recall from out last blog, the environment is the world the agent interacts with. In the case of the South Pole Bebop, the environment is our 9x9 map, the landforms and waterways, the characters, bases, and most importantly, zombies.
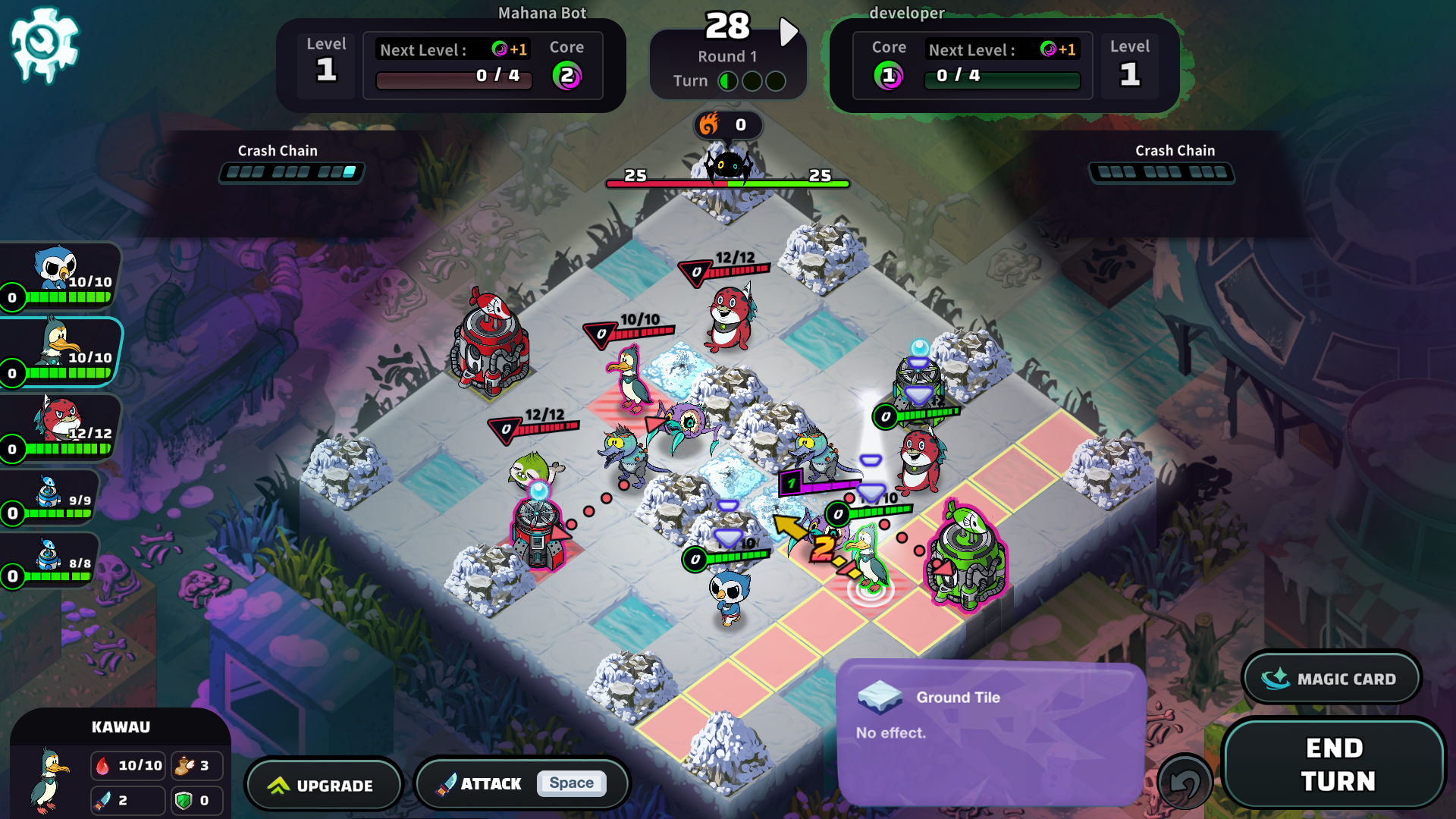
Although it might seem that the game and the environment are the same, you should perceive the environment as a bridge between the game and the agent. The environment consists of:
- Action space: the set of all possible actions the agent can take.
- Observation space: the set of all possible states the agent can be in. Also called “state space”.
- Rewards function: a system determining the rewards and penalties based on action outcomes.
Determine how many agents are acting in the environment. If it is a single-player, then it is a single-agent environment. However, if several agents have different policies or tasks, then it is a multi-agent environment.
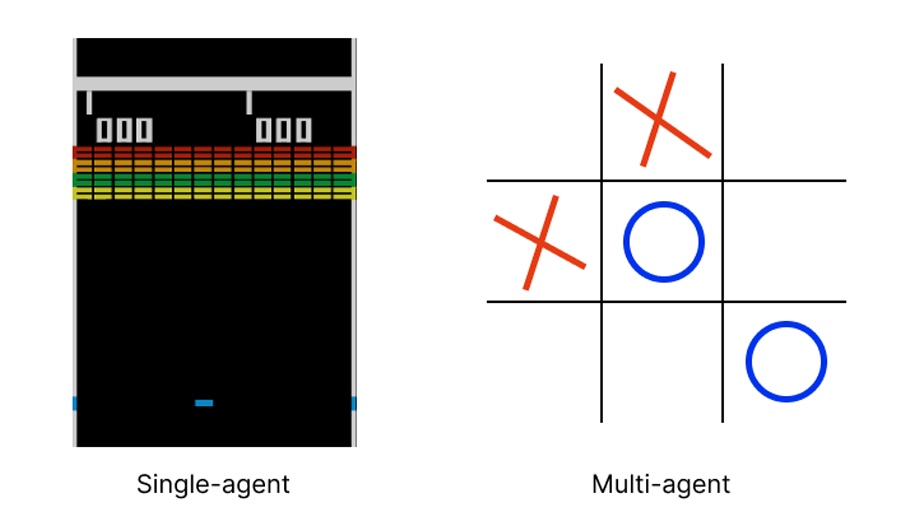
Define the observation space and each agent’s action space in your game. They can be discrete or continuous. Discrete means that it can choose one action unit at a time. Continuous spaces mean that the values lie in certain continuous ranges, e.g. rotation degree.
In the context of South Pole Bebop, the action space includes all move and attack combinations for each character, along with the cards the player can use. The observation space would include the playing characters, their positions, specs, zombie locations, and so on. Ideally, the observation space should only include the information available for a human player as well. You wouldn’t want to play against a player, who knows all your cards in Texas Hold’em, wouldn’t you?
Then, determine what outcomes and actions will result in certain rewards. As the task is to win in the game, we use +1, 0, and -1 rewards depending on the outcome of the game. The goal of reinforcement learning is to make the agent learn, not tell it how to learn, so be careful with the rewards you assign.
There are various ways to implement the environment. We recommend using standardized libraries like Gymnasium (a maintained fork of OpenAI Gym) for a single-agent environment, PettingZoo for a multi-agent environment, or OpenSpiel due to their compatibility with RL frameworks. For Gym-style environments like Gymnasium and PettingZoo, you will need to know and implement the next API specification: reset(), step(), render(), close(). More information and tutorials can be found here.
As South Pole Bebop is a turn-based game between two players, we're using PettingZoo's AECEnv API, tailored for this kind of game.
3. Training agents using RL algorithms
With the game and environment set up, it's time to train the agent. Depending on the defined environment, you need to choose RL algorithms that suit your purpose. Two effective algorithms, previously introduced in the blog, are Deep Q-Network (DQN) and Proximal Policy Optimization (PPO). These are well-suited for discrete action spaces and observation spaces, fitting the characteristics of South Pole Bebop.
However, you should choose algorithms based on the design of your environment. If you're unsure, this resource can help you make an informed decision.
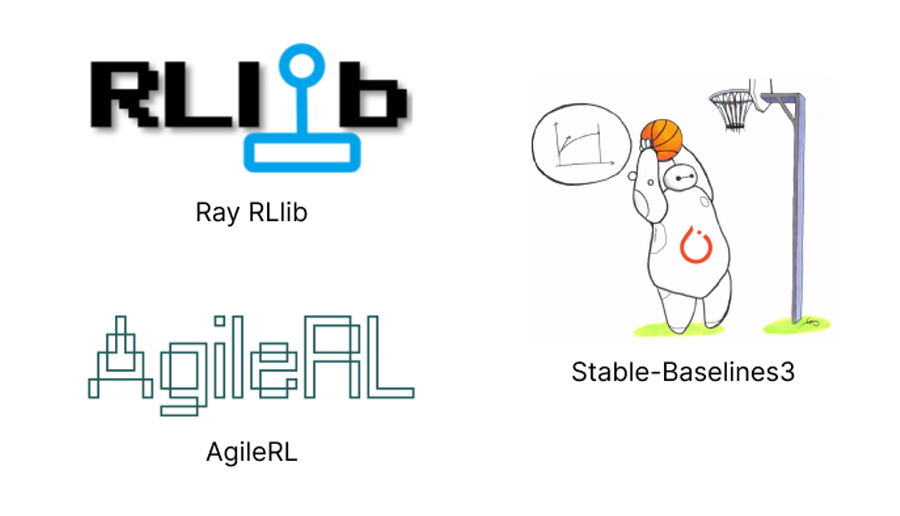
You can directly implement the chosen algorithm or use RL frameworks. The popular choices are Ray RLlib and Stable-Baselines3. While Ray RLlib is a powerful tool with many features along with scalability and cloud, it is difficult to manage its versions due to its sizes and keep up with bug fixes. We also found it difficult to customize. Stable-Baselines3 is also a great library with good documentation. Other options you might want to consider is CleanRL, a lightweight library, and AgileRL, which uses evolutionary hyperparameter optimization.
Conclusion
Once you’ve set up everything, start with default settings and tune hyperparameters and model architectures as you proceed.
Just like Sentience Game Studio, you can utilize deep reinforcement learning and other AI technologies to enhance your games. Finding the right solution may take some trial and error, but with persistence, you will be able to discover the most appropriate model. If you have any inquiries or questions, please don't hesitate to let us know via our inquiry channel. Good luck!
Nargiz Askarbekkyzy, the author, is an AI researcher at Sentience who graduated from KAIST with a major in computer science. She has previously worked in the KAIST lab where she designed and developed retargeting/redirection technology for VR apps. Currently, she is researching and developing deep reinforcement learning models to enhance gaming experiences at Sentience.
Read our previous post: Deep Reinforcement Learning: The Algorithms for Game Dev



