


Intro
심층 강화 학습에 관한 텐투플레이 블로그 2부에 오신 것을 환영합니다! 앞서 1부에서는 강화 학습(RL)의 기본 사항을 소개했습니다. 에이전트가 올바른 결정에 대해 보상을 받고 나쁜 결정에 대해 처벌을 받는 시행착오를 통해, 주어진 작업을 어떻게 수행하는지 알아봤었죠. 또한 딥러닝이 강화학습을 심층강화학습으로 발전시킨 방법에 대해서도 이야기했습니다. 이전 블로그는 여기에서 확인하실 수 있습니다.
오늘은 보다 실용적으로 접근해보려고 하는데요. Deep RL을 적용하여 여러분만의 게임에 뛰어난 결과를 가져다 줄 에이전트를 어떻게 훈련해야 할지 살펴보겠습니다. 함께 파헤쳐봅시다!
1. 타겟 게임 선택
에이전트가 스킬을 구축하고 연마할 놀이터인 게임 자체가 무엇보다 먼저 준비돼 있어야 합니다. 게임 메커니즘의 정확성을 확인하고 프로그래밍 방식으로 상호 작용할 수 있는지 확인하세요.
일반적으로 강화 학습 프레임워크는 Python 프로그래밍 언어를 활용합니다. 따라서 간단한 게임의 경우 Pygame과 같은 오픈 소스 프레임워크를 활용하는 것을 고려해야 합니다. 게임이 Unity에서 개발된 경우 Unity의 ML 에이전트를 RL 프레임워크로 사용할 수 있습니다. 강화 학습 실험을 위한 게임을 특별히 제작하려는 경우 다음 단계에서 논의할 Gymnasium 라이브러리가 적합한 옵션입니다.
다만 어떤 게임이든 게임에 대한 정보를 쉽게 추적할 수 있도록 하는 것이 매우 중요하다는 것을 기억해야 합니다. 우리의 다양한 결정이 게임 상태에 어떤 영향을 미치는지 파악해야 하기 때문입니다.

2. 환경 정의하기
지난 블로그에서 환경이란 에이전트가 상호 작용하는 세계를 뜻한다고 말씀드렸습니다. South Pole Bebop의 경우 환경은 9x9 그리드 맵, 지형과 수로, 캐릭터, 기지, 그리고 가장 중요한 “좀비”가 될 겁니다.
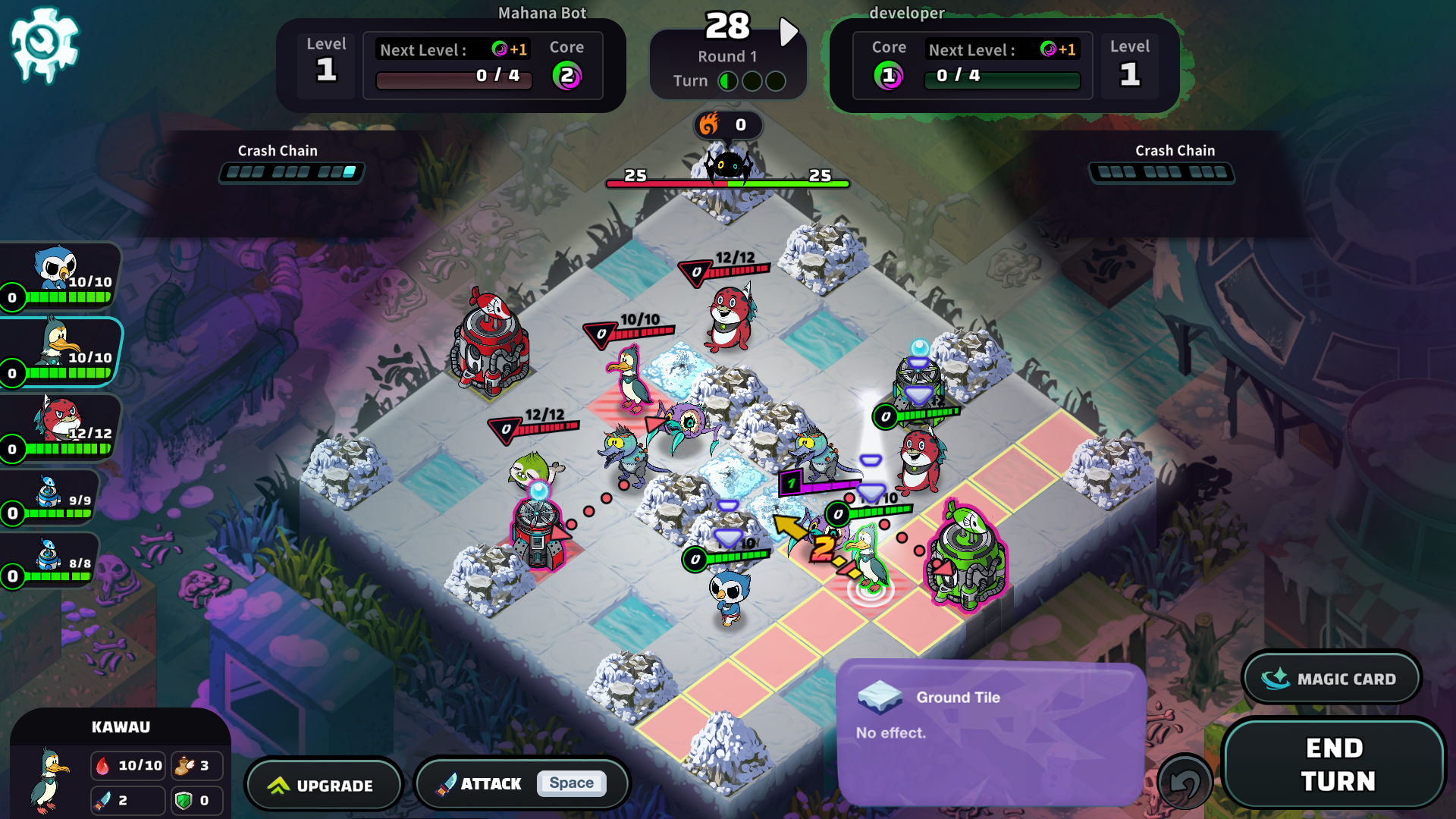
게임과 환경이 동일한 것처럼 보일 수도 있지만 환경은 게임과 에이전트 사이를 연결하는 다리라고 생각하는 것이 좋습니다. 환경은 다음으로 구성됩니다.
- 행동 공간(Action space): 에이전트가 취할 수 있는 모든 가능한 행동의 집합입니다.
- 관찰 공간(Observation space): 에이전트가 있을 수 있는 모든 가능한 상태의 집합입니다. "상태 공간(state space)"이라고도 합니다.
- 보상 기능: 행동 결과에 따라 보상과 처벌을 결정하는 시스템입니다.
환경에서 작동할 에이전트 수를 결정하세요. 싱글 플레이어인 경우 단일 에이전트 환경입니다. 여러 에이전트에 서로 다른 정책이나 작업이 있는 경우 다중 에이전트 환경이라고 할 수 있습니다.
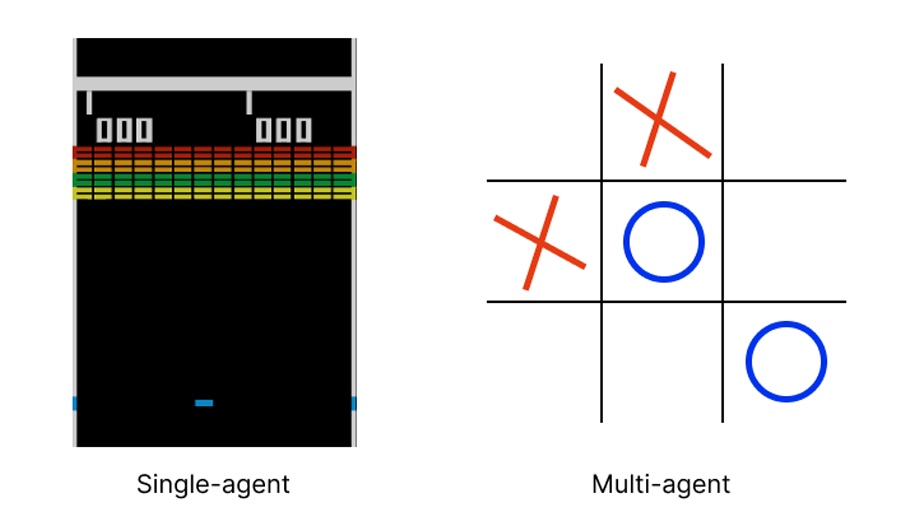
게임에서 관찰 공간과 각 에이전트의 행동 공간을 정의하세요. 이산형(Discrete)이거나 연속형(Continuous)일 수 있습니다. 이산공간은 한 번에 하나의 작업 단위를 선택할 수 있음을 의미합니다. 반면 연속 공간은 회전 각도처럼 값이 특정 연속 범위 내에 있음을 의미하죠.
South Pole Bebop의 경우, 행동 공간에는 플레이어가 사용할 수 있는 카드와 함께 각 캐릭터의 모든 이동 및 공격 조합이 포함됩니다. 관찰 공간에는 플레이하는 캐릭터, 캐릭터의 위치, 캐릭터 스펙, 좀비 위치 등이 포함됩니다. 이상적으로 관찰 공간에는 인간 플레이어가 사용할 수 있는 정보만 포함되어야 합니다. (텍사스 홀덤에서 여러분의 카드를 모두 알고 있는 플레이어와 대결하고 싶지는 않을 테니까요!)
그런 다음 특정 결과값과 행동을 어떤 보상으로 연결시킬지 결정합니다. 게임에서 승리하는 것이 임무이므로 게임 결과에 따라 +1, 0, -1의 보상을 사용합니다. 단, 강화 학습의 목표는 에이전트에게 학습 방법을 알려주는 것이 아니라 학습하게 하는 것이므로 보상을 할당할 때 주의하세요.
환경을 구현하는 방법에는 여러 가지가 있습니다. 단일 에이전트 환경에는 Gymnasium(OpenAI gym의 유지 관리 포크), 다중 에이전트 환경에는 PettingZoo, RL 프레임워크와의 호환성을 위해 OpenSpiel과 같은 표준화된 라이브러리를 사용하는 것이 좋습니다. Gymnasium 및 PettingZoo와 같은 체육관 스타일 환경의 경우 다음 API 사양인 reset(), step(), render(), close()를 이해하고 구현해야 합니다. 자세한 정보와 튜토리얼은 여기에서 확인할 수 있습니다.
South Pole Bebop은 두 플레이어 간의 턴제 게임이므로 이러한 종류의 게임에 맞게 조정된 PettingZoo의 AECEnv API를 사용하고 있습니다.
3. RL 알고리즘을 사용한 에이전트 교육
게임과 환경이 설정되었으면 이제 에이전트를 교육할 차례입니다. 정의된 환경에 따라 목적에 맞는 RL 알고리즘을 선택해야 합니다. 이전에 블로그에서 소개한 두 가지 효과적인 알고리즘은 DQN(Deep Q-Network)과 PPO(Proximal Policy Optimization)입니다. 이는 South Pole Bebop의 특성에 맞게 분리된 행동 공간과 관찰 공간에 적합합니다.
그러나 환경 설계에 따라 알고리즘을 선택해야 합니다. 확실하지 않은 경우 이 리소스의 정보를 바탕으로 결정을 내리는 데 도움을 받을 수 있습니다.
선택한 알고리즘을 직접 적용하거나 혹은 RL 프레임워크를 쓸 수도 있습니다. 널리 사용되는 선택은 Ray RLlib 및 Stable-Baselines3입니다. Ray RLlib는 확장성 및 클라우드와 함께 많은 기능을 갖춘 강력한 도구이지만 크기로 인해 버전을 관리하고 버그 수정을 따라가기가 어렵습니다. 또 사용자 정의도 어렵죠. Stable-Baselines3도 문서화가 잘 된 훌륭한 라이브러리입니다. 고려해야 할 다른 옵션으로는 경량 라이브러리인 CleanRL과 혁신적인 하이퍼파라미터 최적화를 사용하는 AgileRL이 있습니다.
Conclusion
모든 설정을 마쳤으면 기본 설정으로 시작하고 진행하면서 하이퍼파라미터와 모델 아키텍처를 조정하면 됩니다.
여러분도 Sentience Game Studio와 함께 심층강화학습은 물론 다양한 AI 기술을 게임 개선에 적용할 수 있습니다. 단번에 답을 찾을 수 있는 간단한 작업은 아니지만, 다양한 시도를 통해 가장 적합한 모델을 찾아갈 수 있을 겁니다. 궁금한 점이 있으시면 문의 채널을 통해 알려주세요. 모두의 게임에 행운을 빕니다!
센티언스의 AI 연구원 Nargiz Askarbekkyzy는 KAIST에서 컴퓨터 사이언스를 전공했습니다. KAIST 연구실에서 VR 앱의 리타겟팅 및 리디렉션 기술을 설계하고 개발한 경험이 있으며, 현재 센티언스에서는 게임 경험을 향상하기 위한 심층 강화학습 모델을 연구, 개발하고 있습니다.



