


센티언스의 AI 연구원 Nargiz Askarbekkyzy는 KAIST에서 컴퓨터 사이언스를 전공했습니다. KAIST 연구실에서 VR 앱의 리타겟팅 및 리디렉션 기술을 설계하고 개발한 경험이 있으며, 현재 센티언스에서는 게임 경험을 향상하기 위한 심층 강화학습 모델을 연구, 개발하고 있습니다.
Intro
2016년, 구글 딥마인드가 컴퓨터 프로그램 알파고[1]를 선보인 것을 모두 기억하실 겁니다. 어려운 전략 게임으로 알려져 있는 바둑(Go)에서 세계 챔피언을 무너뜨리며 충격을 안겼죠. 딱 3년 뒤, OpenAI는 AI 플레이어로 구성된 OpenAI Five라는 팀을 만들었고, 이들은 Dota2 월드 토너먼트인 The International 2018의 챔피언을 상대로 한 대결에서 승리를 거뒀습니다.[2] 단순히 운이 좋아서 얻은 승리라고 보기는 어렵습니다. 강화학습의 원리를 기반으로 한 정교하고 수준 높은 접근법에 의한 것이라고 할 수 있죠. 강화학습 시리즈의 첫 번째 블로그로써, 이번에는 강화 학습의 세계에 대해 자세히 알아보고 핵심 원리와 세부 내용에 대해 설명해 보겠습니다.
강화학습과 다른 머신러닝 패러다임의 차이
강화학습은 머신러닝이라는 상위 영역 속 하나의 패러다임입니다. 에이전트(agent)가 일련의 시행착오를 통해 역동적으로 변화하는 환경과 상호작용하면서 행동을 학습하는 작업이죠. [3] 정적인 데이터셋에 의존하는 지도학습이나 비지도학습과는 달리, 강화학습은 의사결정에 초점을 맞춘 상호작용적인 요소가 있다는 점에서 차이가 있습니다. (Figure 1)
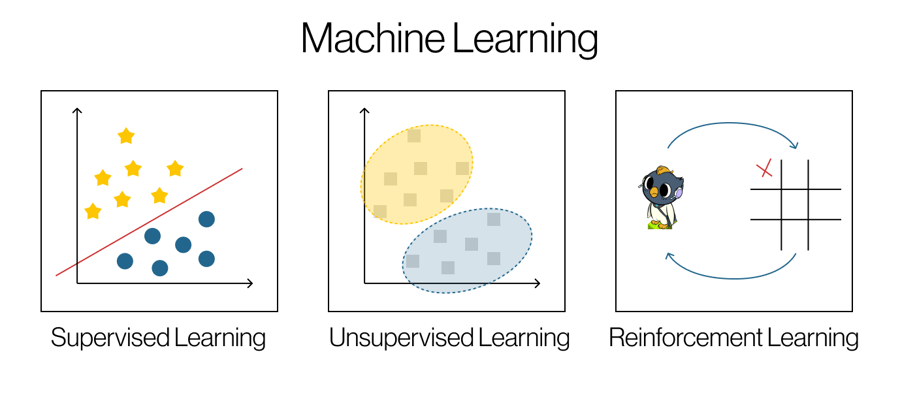
Figure 1. 머신 러닝 패러다임
강화학습의 구성요소와 용어
여기서 에이전트는 무엇이고, 또 환경은 무엇을 뜻하는 걸까요? 컴퓨터 프로그램의 학습법에 대해 설명하기 전에, 이해를 돕기 위해 몇 가지 중요한 구성 요소와 용어에 대해서 소개해드리겠습니다.
- 에이전트(Agent)는 행동을 선택하고 실행하는 일종의 봇입니다.
- 환경(Environment)은 에이전트가 작동하는 세계입니다. 예를 들어 체스 게임이라고 하면, 체스보드와 말들은 환경이고 플레이어-봇은 에이전트라고 할 수 있습니다.
- 행동(Action)은 에이전트가 선택하고 수행할 수 있는 가능한 상호작용을 말합니다.
- 상태(State)는 환경의 현재 상태에 대한 정보입니다.
- 보상(Reward)은 에이전트의 행동에 따른 결과로써 주어지는 점수입니다.
- 정책(Policy)은 에이전트의 전략으로, 주어진 환경에 에이전트가 어떤 행동을 취할지 가이드합니다.
- 에피소드(Episode)는 시작 상태에서부터 종료 상태까지 일련의 상호작용입니다. 체스게임에서 게임 한 판이 하나의 에피소드가 되겠죠.
강화학습의 사이클
이제 준비가 끝났습니다!
근본적으로, 강화학습은 순환적인 프로세스입니다. 에이전트가 환경의 상태를 관찰합니다. 에이전트는 실행할 수 있는 행동 셋(set)을 가지고 있죠. 그 중에서 하나의 행동을 선택하고, 이 행동은 에이전트에게 보상을 가져다줍니다. 이 보상은 양(+)일 수도, 음(-)일 수도, 또 0일 수도 있습니다. 이러한 보상에 따라 에이전트는 정책을 업데이트합니다. 에이전트의 행동은 환경에 변화를 가져오고 새로운 상태를 만들어내며 동일한 과정이 순환적으로 반복됩니다. (Figure 2) [4]
.png)
Figure 2. 강화 학습 개념
에이전트의 최우선 목표는 시간에 따라 축적되는 보상을 최대화하는 것입니다. 에이전트는 어떤 행동을 취해야 할지에 대해 어떠한 명령도 받지 않고, 오직 보상의 측면에서만 영향을 받고 행동합니다. 따라서 각각 반복할 때마다 에이전트는 의사결정 프로세스나 정책을 다시 검토하며, 선호하는 결과로 이어지는 행동에 우선순위를 두도록 학습합니다. 경험을 많이 축적할 수록, 에이전트는 과제를 점점 더 잘 수행할 수 있습니다.
강화학습의 알고리즘
강화학습에는 다양한 알고리즘과 방법론을 적용할 수 있으며 크게 두 그룹으로 나눌 수 있습니다.
- 가치 기반: 가치함수를 추정합니다. 에이전트가 특정 상태에서 얼마나 좋은지 혹은 유리한지를 나타냅니다. [4]
- 가치함수 중 Q함수는 특정 상태 s에서 주어진 행동 a를 했을 때 누적 보상의 기대값을 추정합니다.
- 정책 기반: 가치 함수에 의존하지 않으며, 정책을 직접 학습하고 최적화하는 방법입니다. 여기서 정책은 전략이며, 상태를 모든 행동에 대한 확률 분포로 매핑하여 표현됩니다.
하지만 더 복잡한 설정에서는 어떨까요? 행동 공간(action space)이 커지고 환경이 정교해지는 경우, 위의 방법을 쓰는 것은 매우 까다로워집니다. 가능한 수많은 상태와 행동의 관계를 기억하기가 어렵기 때문이죠. 심층 신경망(Deep Neural Networks)을 활용하여 이 문제를 해결할 수 있는데, 이것이 바로 심층 강화학습(Deep Reinforcement Learning)입니다.
심층 강화학습 알고리즘의 예로,
- 가치 기반 알고리즘 중 Deep Q Network(DQN)는 Q함수를 추정하기 위해 심층 신경망을 활용합니다.[5]
- 정책 기반 알고리즘 중 Proximal Policy Optimization(PPO)는 정책의 업데이트를 위해 심층 신경망을 활용합니다. [6]
센티언스에서는 현재 개발 중인 게임 South Pole Bebop의 스마트 봇을 개발하기 위해 위의 DQN과 PPO를 모두 탐색해왔습니다.
Conclusion
강화학습은 제대로 활용하면 대단한 결과물을 만들어낼 수 있는 강력한 도구입니다. 다음 블로그에서는 강화학습에 대해 좀 더 실용적으로 접근해 볼 텐데요. 앞서 말씀드린 게임 South Pole Bebop에서 심층 강화학습 모델을 어떻게 활용하고 있는지 경험을 공유하고자 합니다. 또 강화학습을 여러분들의 상황에 맞게 적용할 수 있도록, 도움이 될 만한 리소스와 라이브러리, 툴도 공유해 보겠습니다. 여러분과 함께 AI 세계를 파헤쳐 볼 다음 게시물도 기대해주시길 바랍니다.
References:
[1] “AlphaGo,” Google DeepMind. https://deepmind.google/technologies/alphago/
[2] “OpenAI Five defeats Dota 2 world champions,” openai.com. https://openai.com/research/openai-five-defeats-dota-2-world-champions
[3] L. P. Kaelbling, M. L. Littman, and A. W. Moore, “Reinforcement Learning: A Survey,” Journal of Artificial Intelligence Research, 1996, doi: https://doi.org/10.48550/arXiv.cs/9605103.
[4] R. Sutton and A. Barto, “Reinforcement Learning An Introduction second edition.” Available: https://www.andrew.cmu.edu/course/10-703/textbook/BartoSutton.pdf
[5] V. Mnih et al., “Playing Atari with Deep Reinforcement Learning,” arXiv.org, 2013. https://arxiv.org/abs/1312.5602
[6] J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal Policy Optimization Algorithms,” arXiv.org, 2017. https://arxiv.org/abs/1707.06347




